外观
k-Nearest Neighbor
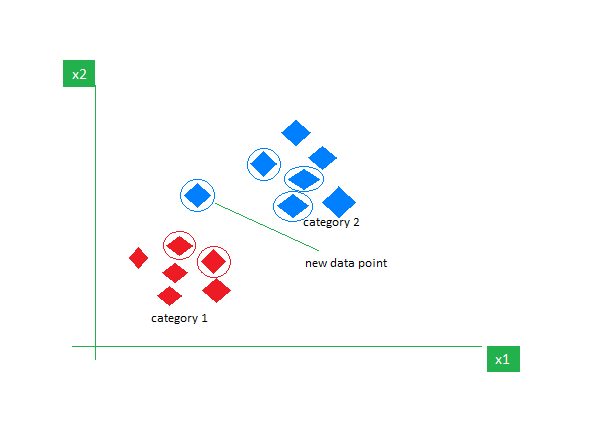
核心思想:根据待分类样本的K个最近邻样本的类别,来预测待分类样本的类别。
为待分类样本找 K 个邻居,看这些邻居多数属于哪类
KNN 属于监督学习,因为它需要使用带有标签的训练数据来学习。
聚类算法是一种无监督学习算法,它可以将数据分为不同的组,而不需要事先知道数据的类别。
计算两点距离,可用毕达哥拉斯公式
用于数据挖掘、机器学习